CursorやClineなどで生成AIを使ってコーディングをしていると、Reasoningモデルとか、Thinkingモードとか、そういったワードに出会うことが多い。これらが意味することについて理解できてないと感じていた。
何かを学ぶとき、資料を読むだけではなく手を動かしてみると理解が早くなる。そこでChatGPTのDeep Researchでハンズオン資料を作り、それを元に学ぶと効率が良いのではないかと考えた。今回の記事ではハンズオンの作成と実施の過程をまとめておく。
ハンズオン資料をDeep Researchで作る
次のように質問してDeep Researchでハンズオン資料を作る。

すると https://chatgpt.com/share/6819d686-5ae0-8010-8196-d532528dc82a のような資料が作られた。
- 序文
- 実験の章の一部

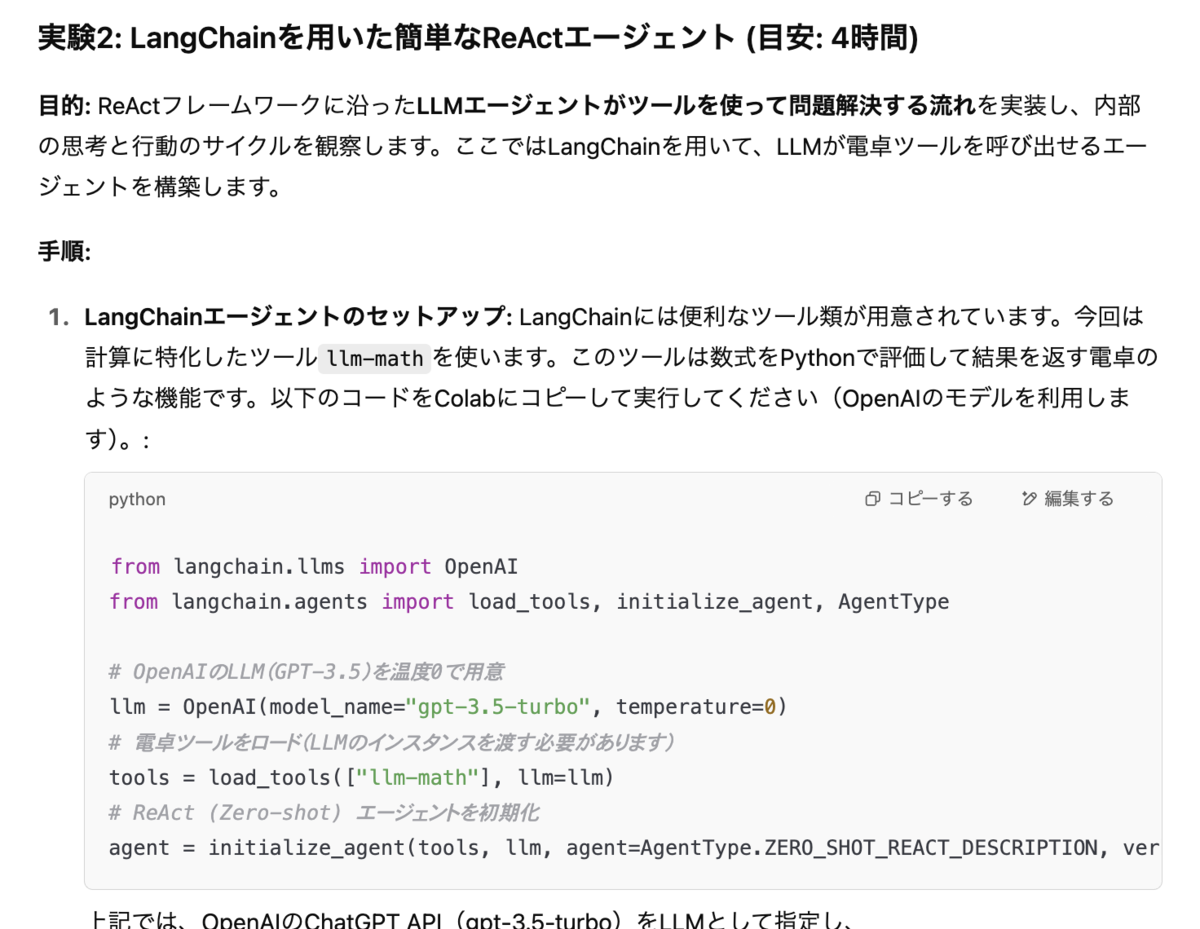
見出しはこういう感じ。
- はじめに
- LLMの思考・推論に関する重要なコアコンセプト
- チェーン・オブ・ソート(Chain-of-Thought)プロンプティング
- ReAct(推論+行動)フレームワーク
- ツールの活用による拡張 (LLM Tool Use)
- メタ認知プロンプティング(自己認識・自己評価プロンプト)
- ハンズオン:推論パターンの実践(Google Colab)
- 準備: Colab環境セットアップ (目安: 0.5時間)
- 実験1: チェーン・オブ・ソートで数学問題を解く (目安: 2時間)
- 実験2: LangChainを用いた簡単なReActエージェント (目安: 4時間)
- 実験3: モデルの自己反省プロンプトを試す (目安: 1.5時間)
- おわりに:学習計画のまとめと今後の展望
Google Colabで実践する
資料ができたので、コアコンセプトの資料を読んだ後、ハンズオンに取り組んだ。
実施すると、ハンズオン資料のコードのままだとうまく動かなかったり、実際に理解したいことと微妙に外れていたりした。今回学びたい領域が新しい領域なため、Deep Researchでも細かい部分はうまくいかなかったのかなと思う。
そこで資料自体を批判的に捉え、違和感があった時やうまく動かない時は自分で調査をし、学びたいことを適切に行うための実装に変更しながら進めていった。このやり方はむしろ理解を深められて良かった。
またハンズオン資料をそのままやるだけでなく、あえて脱線して気になったことを深掘りすることも大切だった。僕の場合ReActフレームワークが具体的にどういう動きをするかが非常に気になったため、debugログを出して1つずつ動きを確認していった。結構時間がかかったが、今のコーディングエージェントがどう動いているかの基本部分を理解できた気がする。
最終的にできたものは https://github.com/shibayu36/playground/blob/main/ai-reasoning-study/AI_Reasoning_Study.ipynb
学んだこと
- LLMにおけるReasoningが何かというのは難しいが、LLMの推論能力や推論させる(論理的に考えさせる)ための方法的な意味で使われている
- 論理的に考えさせるためには、ステップを区切って一つずつ思考させるためのCoT、思考とアクションを繰り返すReAct、出力に対し自己反省させて正しいものに修正する自己反省プロンプトなどいろんな手法がある
- ReActについては、今のコーディングエージェントのtool callの仕組みの理解に繋がった。また改めて記事にしたい
まとめ
今回はLLMのReasoningという自分の知りたい領域について、Deep Researchでハンズオン資料を作って学ぶという方法を試してみた。入門するにはなかなか良い資料ができたし、ハンズオン資料を使いながらその間違いを修正していくくらいの気持ちでやっていくと理解が深まった。
ReAct周りを深掘りして追いかけたことでコーディングエージェントがやっていることの一部を理解できた。これについては別で記事を書こうと思う。