前回の自分の知りたい領域をDeep Researchでハンズオン資料を作って学ぶの記事でDeep ResearchでReasoningを理解するためのハンズオン資料を作った。その実践の中でReActの動きを深掘りしたら、ClineやCursor Agentのようなコーディングエージェントの動きの基本を少し理解できたように感じた。
そこで今回はReActの動きを深掘りした内容をまとめておく。もし間違ったことを書いていたら指摘してほしい。
AIエージェントにおけるReActとは
ReAct Prompting | Prompt Engineering Guideに詳しい情報が載っている。
簡単に言うと、「推論(Reasoning)」と「行動(Acting)」を組み合わせて、AIがより複雑なタスクを遂行できるようにするためのフレームワークである。最初のステップから以下の3ステップをどんどん繰り返していき、最終的に答えを導き出すようになっている。
- 推論 (Reasoning): 観察した内容に基づき「次に何をすべきか」をモデルが考え、解決策を計画する
- 行動 (Action): 推論の結果、必要ならモデルが外部のツールやデータにアクセスする行動を起こす(たとえば電卓を使う、ウェブ検索をするなど)
- 結果の観察: 行動によって得られた結果を観察し、それを踏まえて次の推論に活かす
CoTプロンプティングをさらに発展させて、段階的な推論や外部ツールとの連携をできるようにしたものと言えそう。
挙動を詳しく追いかける
この定義だけだと実際に何をしているか分からないので、LangChainを用いた簡単なReActエージェントを作り、さらにdebugログを有効にして挙動を詳しく追いかけた。https://github.com/shibayu36/playground/blob/main/ai-reasoning-study/AI_Reasoning_Study.ipynb の「実験2: LangChainを用いた簡単なReActエージェント」の部分で試している。
まずgpt-4o-miniを使い、電卓ツールであるllm-mathをロードしたものを用意する。さらに詳細な実行ログを得るために、langchain.debug = True を設定する。
from langchain_openai import ChatOpenAI from langchain.agents import load_tools, initialize_agent, AgentType import langchain # デバッグログを有効にする langchain.debug = True # OpenAIのLLM(GPT-4o-mini)を用意 llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0) # 電卓ツールをロード tools = load_tools(["llm-math"], llm=llm) # ReAct (Zero-shot) エージェントを初期化 agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
そしてagent.runで実行を行う。質問文は「ある店舗が製品を100ドルで販売しています。20%割引した後10%値上げしました。最終価格はいくら?」となっていて、これを解くには電卓ツールを使うのが楽という状況になっている。
question = "ある店舗が製品を100ドルで販売しています。20%割引した後10%値上げしました。最終価格はいくら?" response = agent.run(question) print("最終的なエージェントからの回答:", response)
ではこのdebugログを見ながら、ReActの具体的な挙動を詳しく追いかけていこう。
初期プロンプト
初期プロンプトには以下のとおり。
Human: Answer the following questions as best you can. You have access to the following tools: Calculator(*args: Any, callbacks: Union[list[langchain_core.callbacks.base.BaseCallbackHandler], langchain_core.callbacks.base.BaseCallbackManager, NoneType] = None, tags: Optional[list[str]] = None, metadata: Optional[dict[str, Any]] = None, **kwargs: Any) -> Any - Useful for when you need to answer questions about math. Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [Calculator] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can repeat N times) Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! Question: ある店舗が製品を100ドルで販売しています。20%割引した後10%値上げしました。最終価格はいくら? Thought:
これを見ると次のようにプロンプトで命令を出している。
- toolの一覧と使い方を初期プロンプトで提供する
- Question, Thought, Action, Action Input, Observationの出力のフォーマットを指定する
- Thought/Action/Action Input/Observationを何回もループしてFinal Answerまで辿り着いたら終了するという計画を提供する
- そして最初のQuestion:とThought:を始める
またそれぞれのラベルごとの役割を簡単にまとめると
- Question: 質問文
- Thought: 次に何をすべきかを考えてLLMに出力させるためのラベル
- Action: 実行するアクションを指定するラベル。今回だったらCalculatorを使うときに使う
- Action Input: アクションに渡す入力。Calculatorを使うなら計算式を渡す
- Observation: アクションの実行結果
- Final Answer: 最終的な回答。この出力があったら実行が完了したとみなす
初回のCalculator Actionを実行しろという命令を受け取る
初期プロンプトから開始したとき、まず最初のLLMからのレスポンスはこのようになっていた。
最初の価格は100ドルです。まず、20%の割引を計算し、その後10%の値上げを計算する必要があります。 Action: Calculator Action Input: 100 * 0.2
つまりLLMからどのActionをどの引数で実行するかを受け取って、ここで出力が止まっている。
なぜここで出力が止まっているかというと、LLMにプロンプトを渡すときにstop wordsとしてObservationを指定しているためだ。最初に指定したフォーマットではAction Inputの後はObservation(=Action実行結果を出力)するため、LLMがObservationを出力した瞬間に停止し、stop wordsの前のAction Inputまででレスポンスを返している。
Entering Chain run with input:
{
"input": "ある店舗が製品を100ドルで販売しています。20%割引した後10%値上げしました。最終価格はいくら?",
"agent_scratchpad": "",
"stop": [
"\nObservation:",
"\n\tObservation:"
]
}
Calculator実行のための引数をさらに詳細に得る
LLMからCalculatorを使えという指令が返ってきたが、続いてクライアント側がPythonのnumexpr libraryにそのまま与えられる計算式を得るために、次のプロンプトを追加発行してLLMにリクエストしている。
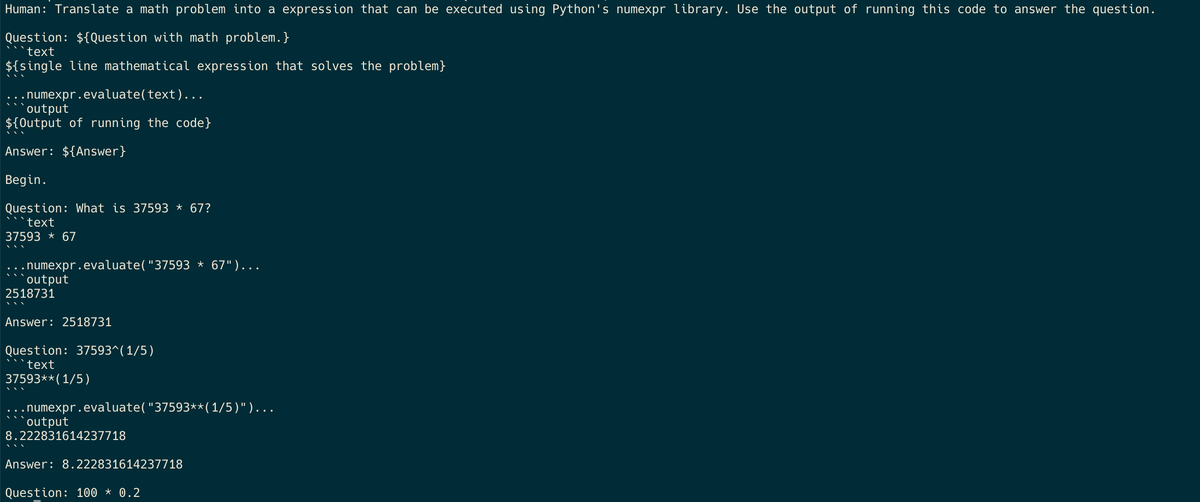
このプロンプトをどこで定義しているかというと、llm_math側の https://github.com/langchain-ai/langchain/blob/1ebcbf1d11578cb55db26013c745dc1e5722966e/libs/langchain/langchain/chains/llm_math/prompt.py#L4-L44 の部分。CalculatorのActionを検知すると、このプロンプトを使ってLLMにリクエストを行い、Actionを実行できる引数をさらに得ようとしている。FewShotを活用してフォーマットを固定している。
その後のLLMからのレスポンスはこちら。
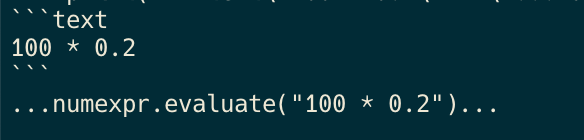
レスポンスではnumexprの実行コードが返ってきている。先ほどのFewShotのフォーマットにしたがっているが、outputという部分が出てこないのは、こちらでもstopを活用しているから。
{
"question": "100 * 0.2",
"stop": [
"```output"
]
}
Calculatorの実行
この後すぐに計算が実行されてAnswer 20.0というのが返っている。これはllm_math側で```textという出力がきたら、その結果をnumexpr.evaluateに通すという実装になっているからっぽい。
これによりクライアント側でCalculatorが実行されて、次のプロンプトに活用される。
次のThoughtへ
ここまででThoughの1loopが終わったので、これまでの情報をすべて入れてLLMへもう一度リクエストを投げる。
Human: Answer the following questions as best you can. You have access to the following tools: (ここに最初のプロンプトが全て入っている) Question: ある店舗が製品を100ドルで販売しています。20%割引した後10%値上げしました。最終価格はいくら? Thought:最初の価格は100ドルです。まず、20%の割引を計算し、その後10%の値上げを計算する必要があります。 Action: Calculator Action Input: 100 * 0.2 Observation: Answer: 20.0 Thought:
先ほどのCalculatorの結果がObservationの部分にAnswer: 20.0として含まれ、もう一度Thoughtフェーズに入ってという命令を送っている。
その後のLLMからのレスポンスはこちら。
20ドルの割引が適用されるので、最初の価格から20ドルを引きます。 Action: Calculator Action Input: 100 - 20
またCalculatorを使えという指令がやってくる。この結果、「Calculator実行のための引数をさらに詳細に得る」のフェーズに戻ってループする。
ループを繰り返し、Final AnswerをLLMがレスポンスするまで続ける
あとはこのThought -> Action -> ObservationのループをFinal Answerが出るまで繰り返す。
最終的にこのようなプロンプトでリクエストされ
Human: Answer the following questions as best you can. You have access to the following tools: (ここに最初のプロンプトが全て入っている) Question: ある店舗が製品を100ドルで販売しています。20%割引した後10%値上げしました。最終価格はいくら? Thought:最初の価格は100ドルです。まず、20%の割引を計算し、その後10%の値上げを計算する必要があります。 Action: Calculator Action Input: 100 * 0.2 Observation: Answer: 20.0 Thought:20ドルの割引が適用されるので、最初の価格から20ドルを引きます。 Action: Calculator Action Input: 100 - 20 Observation: Answer: 80 Thought:割引後の価格は80ドルです。次に、この価格に10%の値上げを計算します。 Action: Calculator Action Input: 80 * 0.1 Observation: Answer: 8.0 Thought:10%の値上げは8ドルです。次に、割引後の価格にこの値上げを加えます。 Action: Calculator Action Input: 80 + 8 Observation: Answer: 88 Thought:
LLMがFinal Answerを出力し
最終価格は88ドルです。 Final Answer: 88ドル
これで結果が確定して終わる。
挙動の図
最後に調べた挙動の図を簡単にまとめる。
[AI Client] [LLM]
| |
|--初期プロンプト送信-------->|
| (Question + format) |
| |
|<--Thought + Action指令----|
| (Calculator, "100*0.2") |
| |
|--詳細計算式要求----------->|
| (llm_math prompt) |
| |
|<--numexpr形式コード--------|
| ("100 * 0.2") |
| |
|--llm_math実行 |
| ↓ |
| |numexpr.evaluate |
| |("100 * 0.2") |
| ↓ |
|<-結果: "Answer: 20.0" |
| |
|--全履歴+Observation-----> |
| 送信(次のThought要求) |
| |
|<--次のThought+Action----- |
| (Calculator, "100-20") |
| |
| ↓ ループ継続 ↓ |
| |
|--全履歴+最終Observation--->|
| |
|<--Final Answer-----------|
| ("88ドル") |
| |
終了 |
まとめ
ReActはこのように初期プロンプトで「推論」と「行動」を繰り返す方法が示され、それにしたがってLLMにリクエストを投げ、Action実行指令がレスポンスされたときはクライアントで適切にActionを実行してさらにLLMへリクエストを投げるということを繰り返していることが分かった。
この流れは最近のAIエージェントによる実行とMCP serverへのtool callの流れと非常に似ている。おそらくClaude Desktop, Cline, Cursor Agentでは初期プロンプトで同じようなやり方を指定して実現しているのだろう。
またこれを見るとThoughtのループに入るたびにこれまでのコンテキスト全てを渡すようになっている。そのため非常に多くのトークンを消費しそう。この辺りの話がPrompt Cachingの話に繋がってくるのかなと思った。また調べてみたい。