
LLMアプリケーションを作ることがなかったとしても、業務でAIを活用する上で大前提を知っておくと役立ちそうということで、「LLMのプロンプトエンジニアリング」を読んだ。
実際に読んでみると、紹介されているLLMの特性を知っておくと、AIコーディングなどにもかなり役立ちそうで良かった。
たとえばこの本に載っている以下のような特徴は非常に参考になる。
- テキストを一度しか読めず後戻りできない。そのため先に書かれた内容のみを考慮して後に繋げる
- 気が散りやすい。「うまくいけば」役立つかもしれない無用な情報でプロンプトを埋めないようにする
- 人間であるあなたが完全に展開されたプロンプトを理解できないのであれば、LLMも同様に混乱する可能性が非常に高い。
- 導かれる必要がある。何を達成すべきかについて明示的な指示を提供し、必要ならタスクをどのように進めるべきかを示す例を提供すべき。
- 内的な独り言がない。問題について声に出して考えること(思考の連鎖、CoT)を許可されれば、有用な解決策に到達するのがはるかに容易になる
- プロンプトの末尾に近い情報ほど、モデルに大きな影響を与えやすい
- 中間部を喪失しやすい。プロンプトの冒頭と末尾の情報は比較的思い出しやすいが、中間に埋め込まれた情報は活用が難しくなる
適切に構築されたプロンプト構造の話も参考になった。
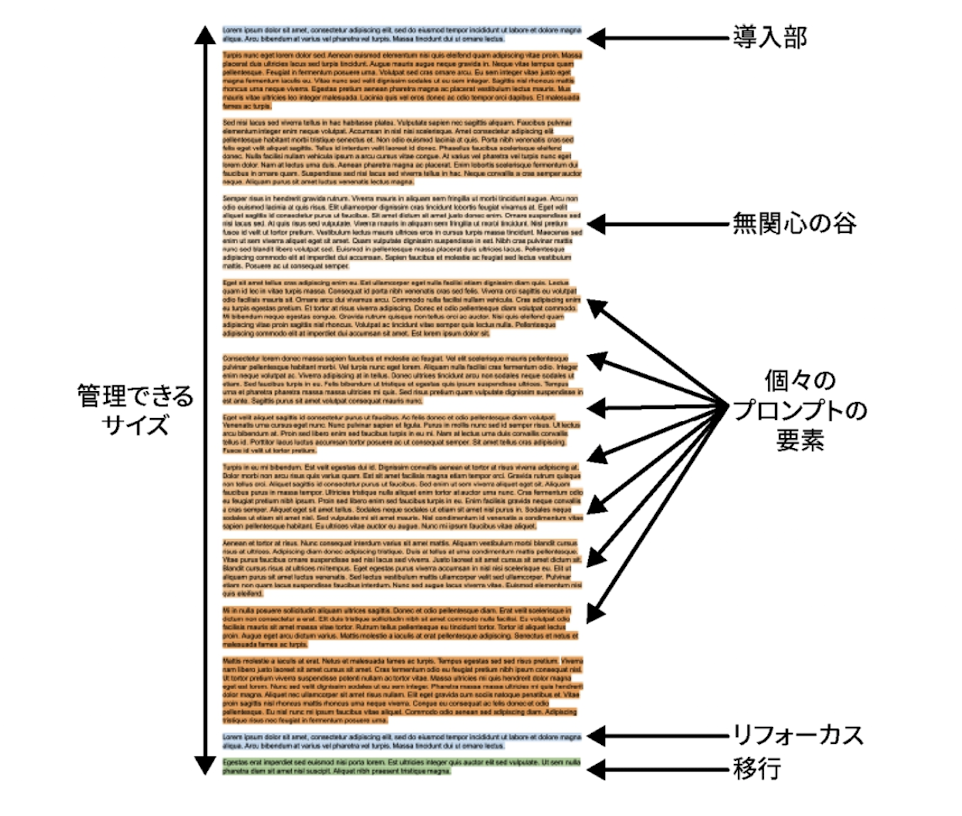
- 構造は、導入 => コンテンツ => リフォーカス => 移行の順
- 導入部: 生成するドキュメントの種類を明確にし、残りのコンテンツに正しくアプローチ。後に続く全ての内容のコンテキストを設定して、モデルに問題を最初から考えさせる役割。早い段階で焦点を絞る
- リフォーカス: すべてのコンテキスト要素を入れ終わったら、最後にもう一度、本題の質問をリマインド。導入部とサンドイッチにする
- 移行: 問題の説明から問題の解決へ移ったことを示す
このように開発へのAI活用の大前提として参考になる内容が多かったのでおすすめ。
読書ノート
- LLMはテキストを一度しか読めず後戻りできない。そのため先に書かれた内容のみを考慮して後に繋げる 79 ⭐️
- 気づき: これが指示はまず最初にと言われる所以っぽい
- 人間の評価者がモデル内部の知識状態を正確に把握して解答例を作るのは困難なため、2つの悪い状況が生じる 90
- 人間がモデル以上の知識を前提に解答例を作る。この場合は「知らないことをでっち上げても構わない」と学習してしまう
- 人間がモデルの知識を過小評価して解答例に曖昧な表現を使う。この場合「確信があっても常にぼかして答える」ことを学習してしまう
- => このような問題をRLHFで
- ユーザーの問題をLLMに解釈できるようにするための条件 122
- トレーニングデータのコンテンツとよく似た形式でなければならない
- 評論形式、Markdown形式などなど
- ユーザーの問題解決に必要なすべての情報が含まれてなければならない
- モデルが問題解決に役立つ補完を生成するように誘導されなければならない
- 自然な終止点があり、世々が自然に止まるようになっていなければならない
- パターンを作り、stop wordが効くように
### プロンプトに組み込むソースを検討する
- プロンプトに組み込むソースは、大きくは「静的」「動的」がある 158
- 静的なコンテンツ
- 質問の明示的な「明確化」162
- 指示だけでなく、なぜそのルールが必要か理由を付ける。殺してはいけない => 殺傷行為は他者の生存権を侵害するため、避けるべきです
- 過度に厳格な表現は避ける。絶対に殺してはいけない => 生命を奪う行為は極めて限定的な状況でのみ検討し、その妥当性を慎重に判断してください
- 暗黙的な指示
- Few-shotプロンプティング 171
- 欠点: Few-shotプロンプティングはモデルが例示された情報に偏る
- 欠点: 誤ったパターンを認識することがある。正常系 => 異常系と並べてFew-shotすると、異常系を出力してしまうなど
- 動的なコンテンツ
- 収集時の考慮点 179
- 動的に収集するときの待ち時間
- 質問の事前に準備できるか
- コンテンツの優先度を比較可能で、後から取捨選択できるか。有用性、依存関係など
- 利用する動的コンテンツを見つける流れ: モデルが知りたそうな情報のマインドマップを作り、アプリケーションが実際に取得可能な情報を洗い出し、まず手軽なものから実装し、プロジェクトが進むにつれて複雑なソースにも手を出す 185
- モデルは与えられた情報を必ず活用しようとする傾向にあるため、無関係なコンテキストまで深読みしてしまう 188
### プロンプトの組み立て
- 適切に構築されたプロンプト構造 216 ⭐️
- 導入部: 生成するドキュメントの種類を明確にし、残りのコンテンツに正しくアプローチ。後に続く全ての内容のコンテキストを設定して、モデルに問題を最初から考えさせる役割。早い段階で焦点を絞る
- リフォーカス: すべてのコンテキスト要素を入れ終わったら、最後にもう一度、本題の質問をリマインド。導入部とサンドイッチにする
- 移行: 問題の説明から問題の解決へ移ったことを示す
- LLMに共通する2つの特徴 216
- コンテキスト内学習: プロンプトの末尾に近い情報ほど、モデルに大きな影響を与えやすい
- 中間部の喪失: プロンプトの冒頭と末尾の情報は比較的思い出しやすいが、中間に埋め込まれた情報は活用が難しくなる傾向
- プロンプト要素の関係を考える時、ポジション(並びと場所)、重要度、依存関係を考慮する 242
- 依存関係 = 必須条件(ある要素を含めるなら前提として必ず入れる)と火両立条件(同時に使えない。要約版と詳細版があった時、どちらも使うと混乱する)がある
- 最小限のプロンプトクラフター:プロンプト要素を順序付けし、トークン予算に収まる限り末尾の要素を可能な限り多く保持する 248
- 補完がどのくらい優れているか 262
- logprobはトークンの各選択肢に対するモデルの信頼度
- トークンの信頼度だけでは文書全体の信頼度はわからないが、テキスト全体のlogprobを合計すると全体的な信頼度を示す
### LLMワークフロー
- ワークフローの構築に必要な手順
- 1. 目標定義: ワークフローが達成する望ましい出力や変更は何か
- 2. タスク指定: 目標を達成する一覧のタスクへ分割。各タスクの入出力を特定
- 3. タスク実装: それぞれを実装し、各タスクが単独で正しく動作することを確認
- 4. ワークフロー全体に接続: ワークフロー全体のコンテキストの中でタスクが正しく機能するように、タスクを調整することもある
- 5. ワークフロー最適化: 品質、パフォーマンス、コスト
### 評価
- LLMアプリにおけるテストスイートは、その変化が改善かリグレッションかを自動的に判別する方法がない。この点が通常のソフトウェアテストと違う 386
- テストを行うLLMとテストを考案するLLMが同一だった場合、テスト結果にバイアスがかかる問題が存在 394
- 評価させる時は、モデルが第三者を採点していると考えさせる方が良い 404
- モデル自体を採点していると考えてしまうと、バイアスにさらされて精度が悪化する
- 人気のベンチマークは、ベンチマーク自体をLLMが学習していくため、徐々に使えなくなってしまう 426
### LLMの特性として覚えておきたいこと
430 ⭐️
- LLM は気が散りやすい
- 「うまくいけば」役立つかもしれない無用な情報でプロンプトを埋めないでください。すべての情報が意味を持つようにしましょう。
- LLM はプロンプトを解読できない
- 人間であるあなたが完全に展開されたプロンプトを理解できないのであれば、LLMも同様に混乱する可能性が非常に高いです。
- LLM は何かに導かれる必要がある
- 何を達成すべきかについて明示的な指示を提供し、適切な場合は、タスクをどのように進めるべきかを示す例を提供してください。
- LLM は超能力者ではない
- プロンプトエンジニアとして、モデルが問題に対処するために必要な情報をプロンプトに含めることはあなたの仕事です。あるいは、モデルにツールと指示を与えて、それを取得できるようにしましょう。
- LLM には内的な独り言がない
- LLM が問題について声に出して考えること(思考の連鎖、CoT)を許可されれば、有用な解決策に到達するのがはるかに容易になります。