複数のpngを全部pdfに結合する処理を書いていて、その中でJPEG圧縮について興味が湧いた。JPEG圧縮全体はまだ全く理解出来てなかったけど、その工程の中のクロマ・サブサンプリングについて調べたのでメモしておく。間違ってる可能性も高いので、ツッコミあれば教えてください。
そもそもJPEGの圧縮の流れ
ChatGPTに聞いたら次の流れのようだ。逆順をたどれば復元できるが、量子化で捨てた分は戻らない。
- 色を人間の感じ方に合わせて変換(RGB → YCbCr)
- 色差成分を間引き(サブサンプリング)
- 画像を 8×8 ピクセルの小さなブロックに分割
- 各ブロックに離散コサイン変換(DCT)をかけて「周波数成分」に分解
- 高い周波数ほど粗く丸める(量子化)=ここが“劣化”ポイント
- ゼロが並びやすい順に並べ直し(ジグザグスキャン)
- ゼロの連続を短い記号で表現し、ハフマン符号でさらに圧縮
これの2でクロマ・サブサンプリングをしている。
YCbCr
RGBからの可逆変換で、RGBと違い色の情報だけサンプリングしやすい。人間は輝度に対して色差の変化を感じにくいことを利用して情報を圧縮することができる。
雑に言うとYは輝度(グレースケール)、Cbは青っぽさ、Crは赤っぽさを表す数字になっていて、この3つを使うことで色を表現する。
クロマ・サブサンプリング
YCbCrでCbCrだけをサンプリングする。imagemagickなどで -sampling-factor 4:2:0 と指定しているが、この情報はクロマ・サブサンプリングに使われている。
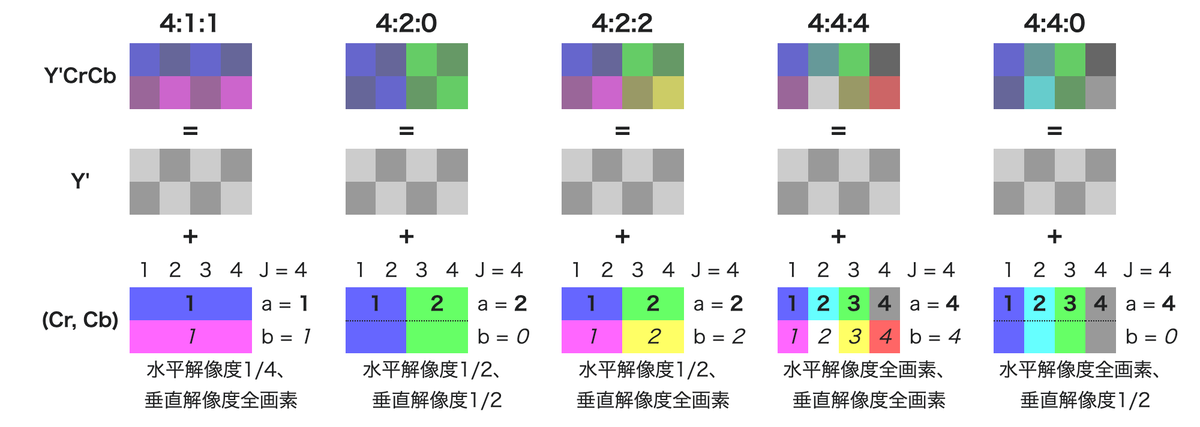
クロマ・サブサンプリング - Wikipediaの図がわかりやすい。4:2:0をJ:a:bと表した時
- J:水平サンプリング基準(概念的な領域の幅)。通常は4。
- a:Jピクセルの最初の行のクロマサンプル(Cr、Cb)の数。
- b:Jピクセルの最初の行と次の行のクロマサンプル(Cr、Cb)の変化量。
と表現される。それぞれのsampling-factorの変換のイメージはWikipediaの画像がわかりやすい。
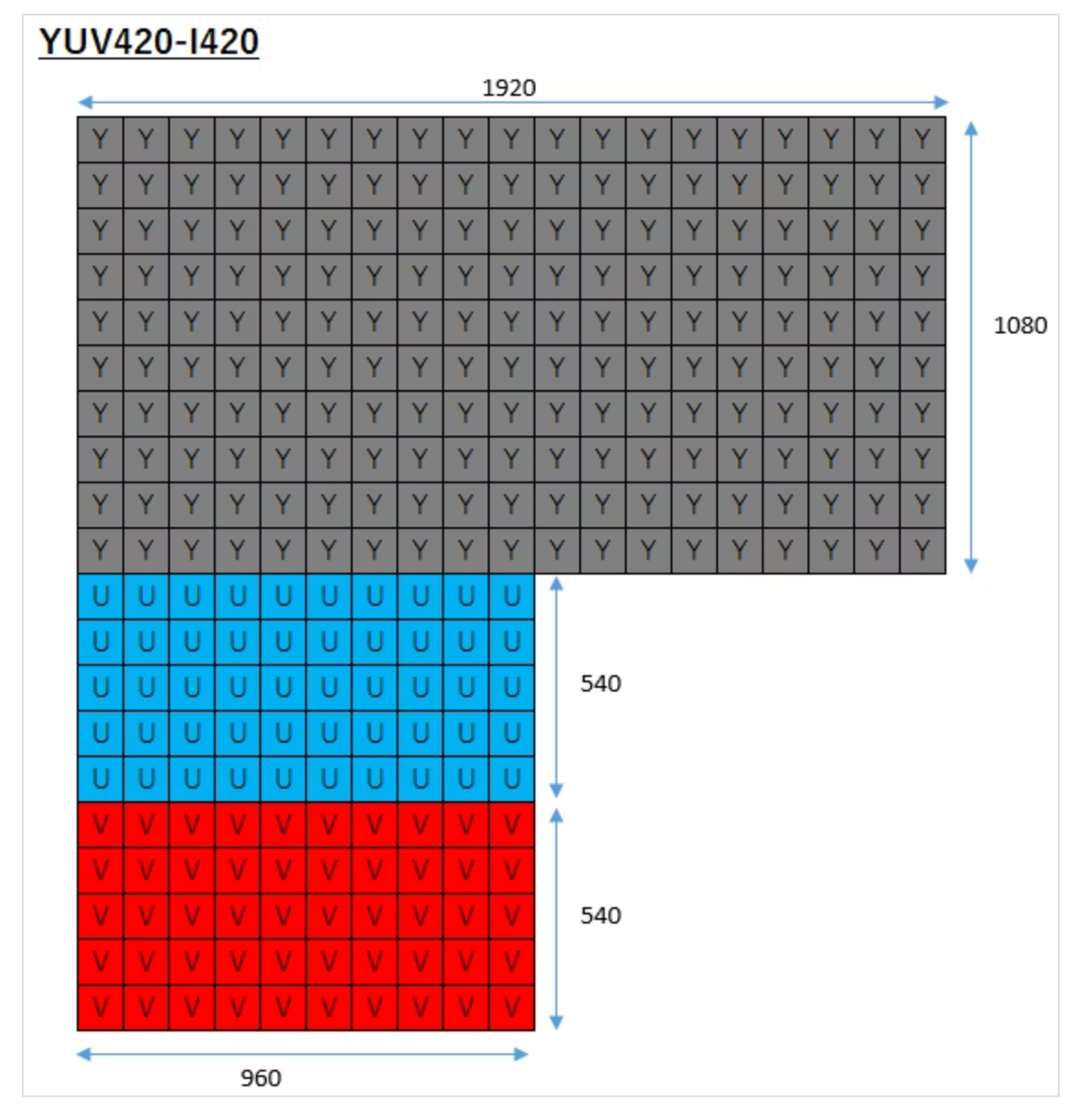
サンプリングした後のフォーマット
データ構造的にサンプリングしただけでデータ量が減るんだっけ?と疑問に思ったが、これはYUVフォーマットという形式を調べるとデータ量が減ることがわかる。参考: YUVフォーマットの違いを世界一分かりやすく解説 #OpenCV - Qiita。
視覚的にはこの図を見るとわかりやすい。