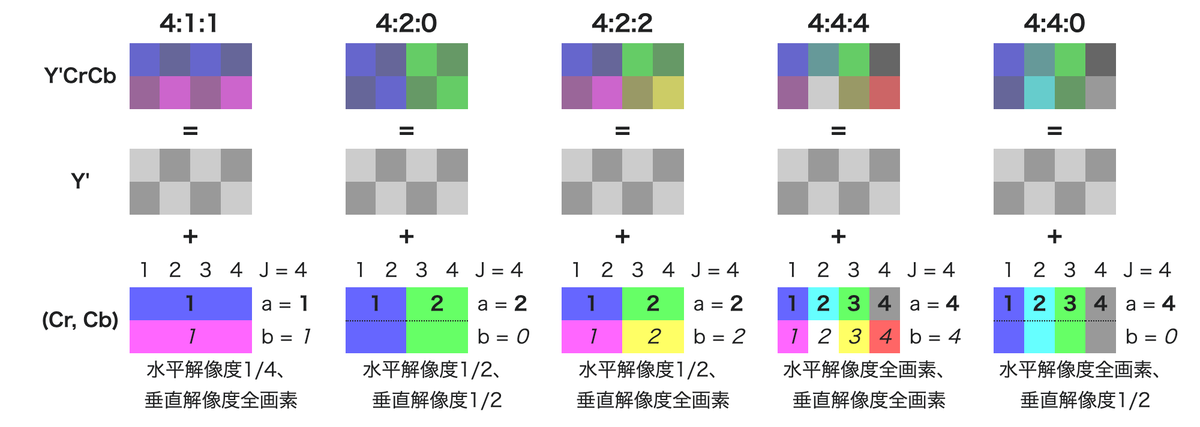
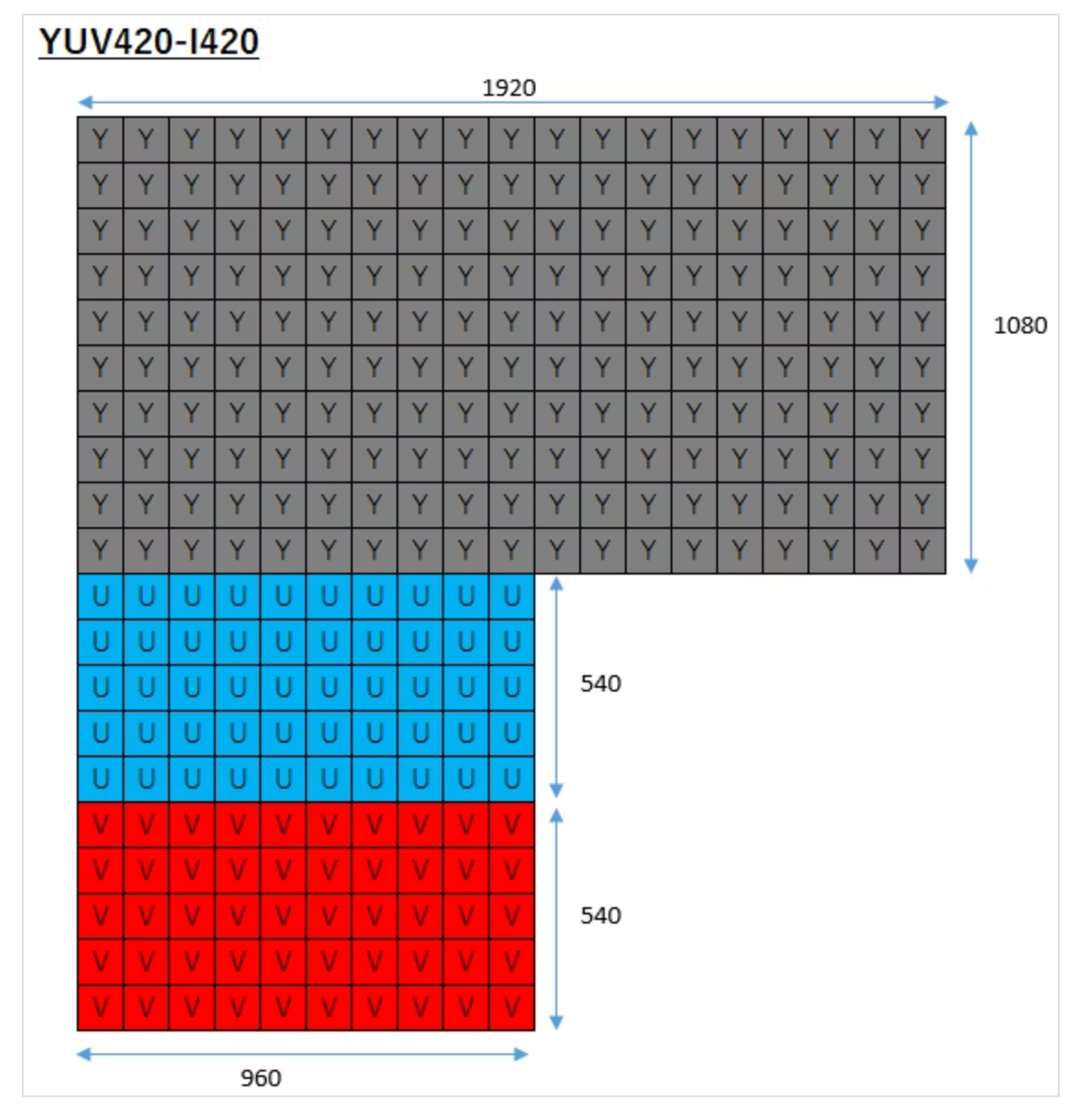
前回紹介したMySQLのスキーマ情報を圧縮して提供するMCPサーバーは、かなりの部分をVibe Codingで作った。その時にVibe Codingのやり方を調べていたのだが、Tipsは色々出てくるものの、具体的にどうAIと会話していったかなどはあまり分からず困っていた。
そこで今回の記事では、このツールの実装時に具体的にどのようにVibe Codingをしたかを紹介する。同じように具体的なやり方が分からず困っている人の参考になれば嬉しい。
今回のMCPサーバーを作った時、全体としては以下のようにVibe Codingをした。
- 機能要件が大体動く部分までは、ほぼコードレビューすらせずに動作確認だけするようなVibe Codingで作る
- テストの最初の構造作りはVibe Codingがうまくいかなかったため、この辺りを自分で用意
- それ以降もここまで、テスト作り・リファクタ・text/template利用などの変更を加えた。Vibe Codingをメインとしながら、うまくいかない部分をちょっとだけ手で更新しつつ実装した
この中で一部の実装の実例を紹介していきたいと思う。今回のレポジトリではこのcommitのtreeまでは、.cursor/配下やdocs/配下も積極的にcomitしているので、その辺りも一緒に見ると分かりやすいと思う。
基本の流れ
- 作り始める前に、チャットで要件を壁打ちしてもらいながらrequirements.mdというファイルを作る
- 何かを実装するときは、まずチャットで設計をしてもらう => それを実現するためのTODOリストも含めてdocsに書き出しをしておく => そのdocsを再度読み込ませてコーディングしてもらうという流れで行う
- ただし複雑な設計じゃなくコンテキスト長の制限を超えないケースならdocsに書き出さずにそのまま実装しても良い
- 作りながら仕様変更や設計変更をしたら、docsに書き出ししておく
今回はCursorのAgentを活用し、modelはGemini 2.5 Proを使っていることが多かった。たまにo4-miniやClaude 3.5 Sonnetを使うこともあった。またmemory bankやMCPサーバーは使わなかった。
実例
requirements.mdの壁打ち
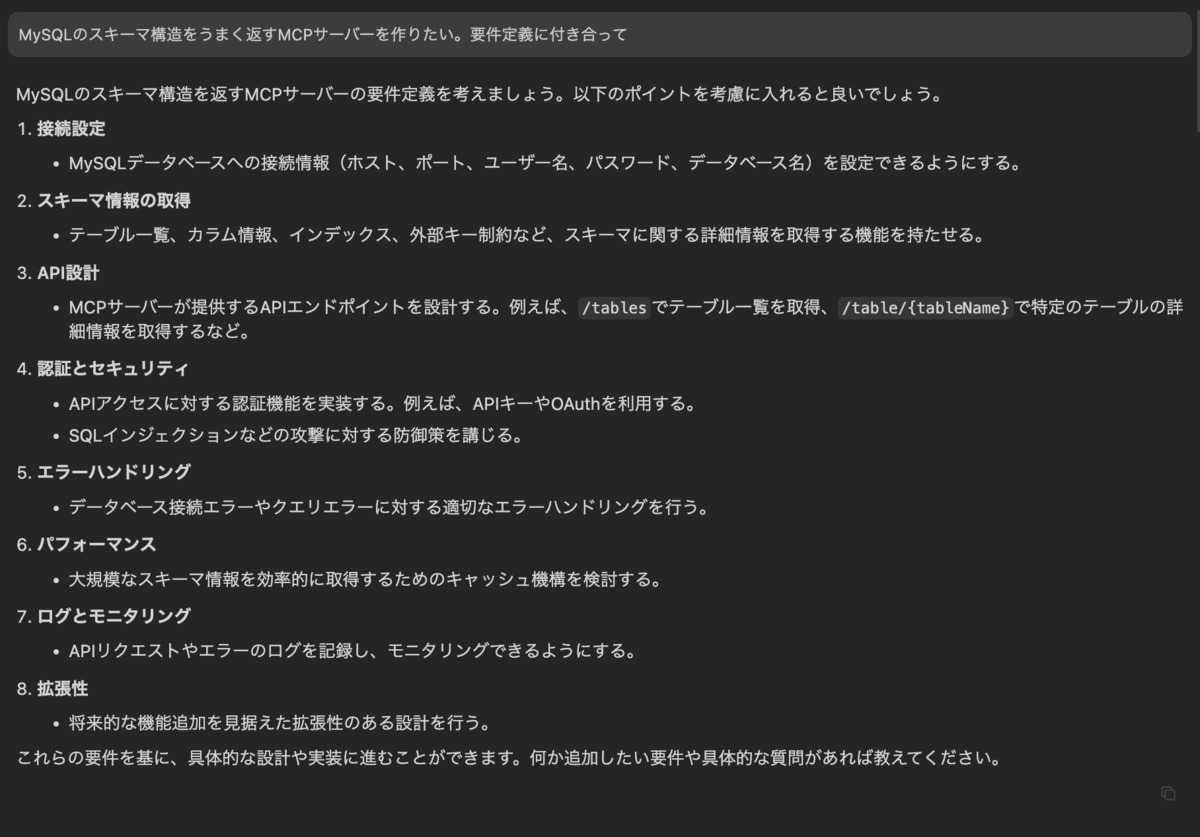
まずは要件定義を壁打ちしてもらった実例から。以下のような質問から開始して要件定義に付き合ってもらった。
その後もかなり雑にチャットを続けていて
やりたい事としては、環境変数でどのデータベースに接続するかを設定した後に、tool callで - テーブル一覧を出力 - テーブル詳細を出力 の2つを出したい
どんな名前のツールにするといいかな?
あたりを質問続けて会話しながら、それっぽいのできたなと思った段階で、「今までの会話をrequirements.mdに反映させてください」と言って書き出してもらった。
その時にできたものがこちら。眺めるとわかるが、実はこの時点ではAIがMCPサーバーの概念を理解していない。
そこで続いてMCPサーバーの概念を理解させながらrequirements.mdを更新することにした。MCPサーバーを実装する時の参考資料である https://modelcontextprotocol.io/quickstart/server が使えると思ったため、ChatGPTで以下のような質問をしてまずサマリー資料を作ってもらった。
MCP Serverを実装するときにAIに参考のために読み込ませる資料を用意したい。 https://modelcontextprotocol.io/quickstart/server の資料を読み込み、 AIに読ませるmarkdownの情報を作って
作った資料をdocs/に配置した後、読み込ませてもう一度requirements.mdを作ったcommitがこちら。MCPサーバーのtoolの概念を理解したようなrequirements.mdができた。
ここまでのdiffも参照してほしい。
list_tablesの実装
続いてlist_tablesという、特定データベースのテーブル一覧のサマリー情報を出力するtool機能を実装した時の実例を紹介する。全体像はこちら。
この時はlist_tablesの実装のためのTODOリストを自分の頭の中に持っていたので、1つずつVibe Codingで実装した。
まずはテーブル名とテーブルコメントだけ出力する部分を作った。これを作るときは次のようにCursorの@参照を使ってdocs/配下を読み込んでまずコード書かずに設計してねと伝えて設計から始めた。大体のチャットの流れ的には
@main.go ではlist_tablesを作っていきたい。まずはコードを書かずにどのような設計にするか考えてみてほしい @docs
とりあえずテーブル名とテーブルコメントを一覧表示するのはどうだろうか
@https://github.com/mark3labs/mcp-go/blob/main/README.md の情報を読み込み、listTablesHandlerが返す内容をもう少し精査して
その後どんどんチャットを繰り返し、それっぽく設計できたなと思ったタイミングで次のように一気にコード生成した。
良いですね。main.goにこの実装を反映して
このような流れで同様にPK,UK,FKの出力部分も作っていった。
text/templateを利用するリファクタリングをした時の実装
これまでに説明したやり方で、全部の機能要件は作っていった。続いてtext/templateを使うようにするリファクタリングの実例も紹介する。
最初にVibe Codingで作ったコードは、テキストの組み立てを文字列結合でひたすらやっていくという実装になっていた。見通しをよくするためにtext/templateを使えないかなと考えたため、Vibe Codingで実現していった。全体像はこれ。
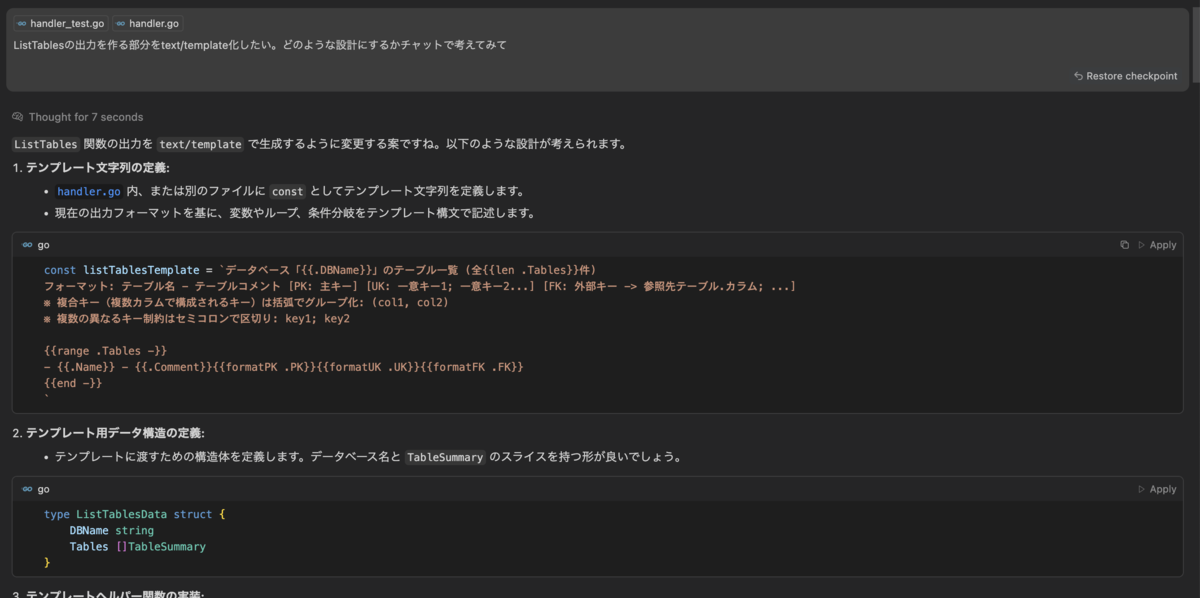
やり方自体はこれまで紹介したのと同様で、まずチャットで設計をしてもらう => それを実現するためのTODOリストも含めてdocsに書き出しをしておく => そのdocsを再度読み込ませてコーディングしてもらうという流れだ。最初はこういう質問から始めて
さらにチャットをどんどん繰り返す。たとえば以下のような質問をしたりしながら繰り返した。
テンプレート系の処理はview.goにすると良いですかね?他に良いファイル名あります?
大体設計ができたなと思ったらdocsに書き出してもらった。その時できたのがこれ(ただしこのdocsをcommitせずに進行したのでdescribe_tablesのtext/template化のものも混ざっている)
そういう方向でいきましょう。今までの設計をdocs/onetime/20250427-use-template.mdに書き出してもらっていいですか?
そのあと実装フェーズに移った。先ほどのドキュメントを読ませた上でさらにTODOリストを作らせて
ステップバイステップでいきましょう。まず何からやるべきですか?
その後1つずつコード生成をして、都度gitのstageに載せ、次のステップを実装という流れを繰り返した。最終的にlist_tablesのtext/template化が完成したタイミングでcommitした。
あとは同様の流れでdescribe_tables側も作成してリファクタが完了した。
Vibe Codingを試して感じたこと
- 今回はいろんなmodelを試した中で、Gemini 2.5 Proがかなり良かった。コンテキスト長が長いからなのかなぜなのかはよく分からない
- ただしGeminiは無駄にコードコメントを書きまくってしまうという特性があり、その部分は非常に面倒だった
- .cursor/rules/配下を整えるのは大前提
- たとえば000-global.mdcのルールがないと、かなり暴走列車でコード生成して辛かった。参考: https://qiita.com/masachaco/items/c56bd601576ed9612f6c
- 他にもGoのテストの実行方法を知らせるために100-go-test.mdcを用意したりなど
- 新しめの技術仕様やライブラリの使い方は別でdocsを用意して必要な時に読み込ませると良い
- 今回はMCPサーバーの実装ドキュメントをまとめたものや、mcp-goの使い方をまとめたものを用意した
- こういうのを手元にいっぱい持っておくのは大事そう
- 今回はVibe Codingを理解するために縛りプレイでエージェントにお任せしたが、書き捨てコードや自分だけでメンテするようなツールでない限り、Vibe CodingでPoCしつつ、その後は自分でコードを調整したり書き直したりした方が良さそう
まとめ
今回は、MySQLのスキーマ情報を返すMCPサーバーをVibe Codingで作った具体的な流れを紹介した。Vibe Codingに関するいろんな記事が出ているが具体的な例があまり無く困っていたので、同じような悩みを持っている人の参考になれば嬉しい。