以前PullRequestからチーム開発の生産性・健全性を測るCLIツールを書いてみた - $shibayu36->blog;のようなことをやってみたのだが、BigQueryにデータを送ることでもう少し柔軟に変更のリードタイム*1などを可視化してみたのでメモ。
BigQueryで可視化するためにやったことは3つ。
- BigQueryにマージされたPullRequest情報を送るスクリプトを作成
- 上記スクリプトをGithub Actionsで動かし、定期的にデータを送る
- BigQueryでViewを作り、Data Studioで可視化
BigQueryにマージされたPullRequest情報を送るスクリプトを作成
こういうイメージ。
import { execFileSync } from "child_process"; import { writeSync } from "fs"; import { BigQuery } from "@google-cloud/bigquery"; import { startOfToday, addDays, parseISO } from "date-fns"; import { fileSync } from "tmp"; // PullRequestの統計情報をBigQueryに入れるスクリプト // // 指定する環境変数 // - GITHUB_TOKEN: repoアクセスできるgithub token // - GOOGLE_APPLICATION_CREDENTIALS: Google Cloud APIsを呼び出すための鍵ファイルへのパス // - BigQueryデータ編集者とBigQueryジョブユーザーのロールが必要 // - See Also: https://cloud.google.com/docs/authentication/production?hl=ja // - PROJECT_ID: Google Cloudのproject id // - START_DATE(optional): 集計対象の始点。ISO8601形式。デフォルトは前日0:00 // - END_DATE(optional): 集計対象の終点。ISO8601形式。デフォルトは当日0:00 // // 実行例 // GITHUB_TOKEN=... GOOGLE_APPLICATION_CREDENTIALS=/path/to/keyfile.json START_DATE=2020-10-05 END_DATE=2020-10-12 yarn --silent ts-node dev-performance-stat/pull-request.ts const QUERY = "org:microsoft"; async function main(): Promise<void> { const startDateISO = process.env.START_DATE; const endDateISO = process.env.END_DATE; const projectId = process.env.PROJECT_ID; const endDate = endDateISO ? parseISO(endDateISO) : startOfToday(); const startDate = startDateISO ? parseISO(startDateISO) : addDays(endDate, -1); console.log("input parameters: ", { projectId, startDate, endDate, }); const prLogs = execFileSync( "merged-pr-stat", [ "log", "--start", startDate.toISOString(), "--end", endDate.toISOString(), "--query", QUERY, "--format", "csv", ], { encoding: "utf8" } ); if (!prLogs) { console.log("No merged pull request"); return; } // loadに渡せるように一時ファイルに書き込む const tmpFile = fileSync(); writeSync(tmpFile.fd, prLogs); const bigquery = new BigQuery({ projectId, }); // 重複を防ぐため、先に該当範囲をDELETEしておく await bigquery.query({ query: `DELETE FROM \`sample_dataset.github_pr_logs\` WHERE @startDate <= mergedAt AND mergedAt <= @endDate`, params: { startDate: startDate.toISOString(), endDate: endDate.toISOString(), }, }); const [job] = await bigquery .dataset("sample_dataset") .table("github_pr_logs") .load(tmpFile.name, { skipLeadingRows: 1, encoding: "UTF-8", autodetect: true, }); console.log(`Job ${job.id} completed.`); const errors = job.status?.errors; if (errors && errors.length > 0) { throw errors; } } main().catch(error => { console.error(error); process.exit(1); });
指定した時間範囲のPullRequest情報をBigQueryに送ってくれる。指定した時間範囲のBigQuery側のデータを削除してくれるようにして、何回実行しても重複が起こらないように工夫した。
このスクリプトによって、https://github.com/shibayu36/merged-pr-stat で出力されるものが自動でBigQueryのスキーマとして認識される。

上記スクリプトをGithub Actionsで動かし、定期的にデータを送る
最近の定期実行はGithub Actionsで行っておくと便利。こんなイメージ。GitHubのsecretsには必要な情報を保存しておく。
name: dev-performance-stat-pull-request on: schedule: - cron: 30 1 * * * # JST 10:30 # 再実行やデバッグ用に手動でも実行可能にしておく workflow_dispatch: inputs: start_date: description: 集計対象の始点。ISO8601形式。 required: false end_date: description: 集計対象の終点。ISO8601形式。 required: false env: TZ: "Asia/Tokyo" jobs: pull-request-stat: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-node@v1 with: node-version: "14" - run: yarn install # GCP_SA_KEYにGCPのキーファイルをbase64化したものを # 入れておけば、GCPの認証の設定をしてくれる。 - uses: GoogleCloudPlatform/github-actions/setup-gcloud@master with: service_account_key: ${{ secrets.GCP_SA_KEY }} export_default_credentials: true - run: yarn --silent ts-node pull-request-to-bigquery.ts env: START_DATE: ${{ github.event.inputs.start_date }} END_DATE: ${{ github.event.inputs.end_date }} GITHUB_TOKEN: ${{ secrets.DEV_PERFORMANCE_GITHUB_TOKEN }} # 失敗に気付けるように、Slackに通知する - name: Slack Notification on Failure uses: rtCamp/action-slack-notify@v2.1.0 if: failure() env: SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK_URL }} SLACK_COLOR: danger SLACK_MESSAGE: pull-request-to-bigquery Failed SLACK_USERNAME: GitHub Action SLACK_ICON_EMOJI: ":github:"
BigQueryでViewを作り、Data Studioで可視化
あとはBigQueryでSQLを使っていい感じに可視化するViewを作り、Data Studioで可視化する。例えば以下はleadTime(1commit〜マージまで)の中央値、timeToMerge(PR作成〜マージまで)の中央値、PullRequest数の28日移動平均を作るSQLである。
WITH -- 対象範囲を出す start_and_end_days AS ( SELECT MIN(DATE_TRUNC(DATE(mergedAt), DAY)) AS start_day, MAX(DATE_TRUNC(DATE(mergedAt), DAY)) AS end_day FROM sample-account.sample_dataset.github_pr_logs), -- 日付の集合を作る date_seq AS ( SELECT date FROM UNNEST(GENERATE_DATE_ARRAY( (SELECT start_day FROM start_and_end_days), (SELECT end_day FROM start_and_end_days) )) AS date ORDER BY date), github_pr_logs AS ( SELECT DATE_TRUNC(DATE(mergedAt), DAY) AS merged_at_trunc, github_pr_logs.* FROM sample-account.sample_dataset.github_pr_logs), -- 1日ごとに各指標を集計していく github_pr_logs_with_median AS ( SELECT date_seq.date, PERCENTILE_CONT(github_pr_logs.leadTimeSeconds, 0.5) OVER (PARTITION BY date_seq.date) AS lead_time_median, PERCENTILE_CONT(github_pr_logs.timeToMergeSeconds, 0.5) OVER (PARTITION BY date_seq.date) AS time_to_merge_median, COUNT(*) OVER (PARTITION BY date_seq.date) AS pr_count, github_pr_logs.* FROM date_seq INNER JOIN github_pr_logs ON date_seq.date >= github_pr_logs.merged_at_trunc AND DATE(github_pr_logs.merged_at_trunc) >= DATE_SUB(date_seq.date, INTERVAL 28 DAY) WHERE -- チーム所属エンジニアで絞り込む github_pr_logs.author IN ("shibayu36", "engineer1", "engineer2") ) SELECT date, MAX(pr_count) AS pr_count, -- hoursに直す MAX(lead_time_median) / 3600 AS lead_time_hours_median, MAX(time_to_merge_median) / 3600 AS time_to_merge_hours_median, FROM github_pr_logs_with_median GROUP BY date ORDER BY date DESC
このSQLを実行すると、このようなデータを取得できる。
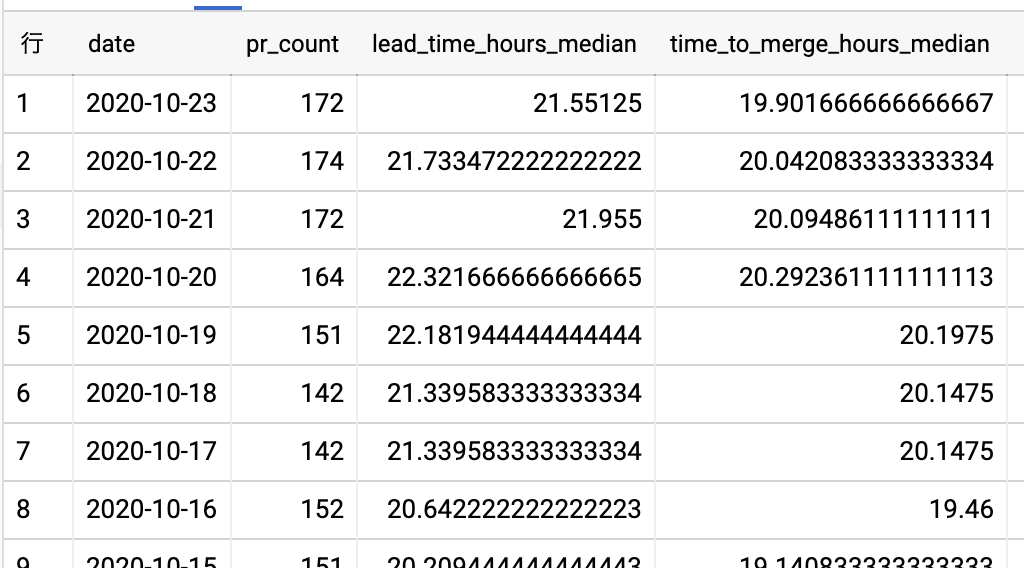
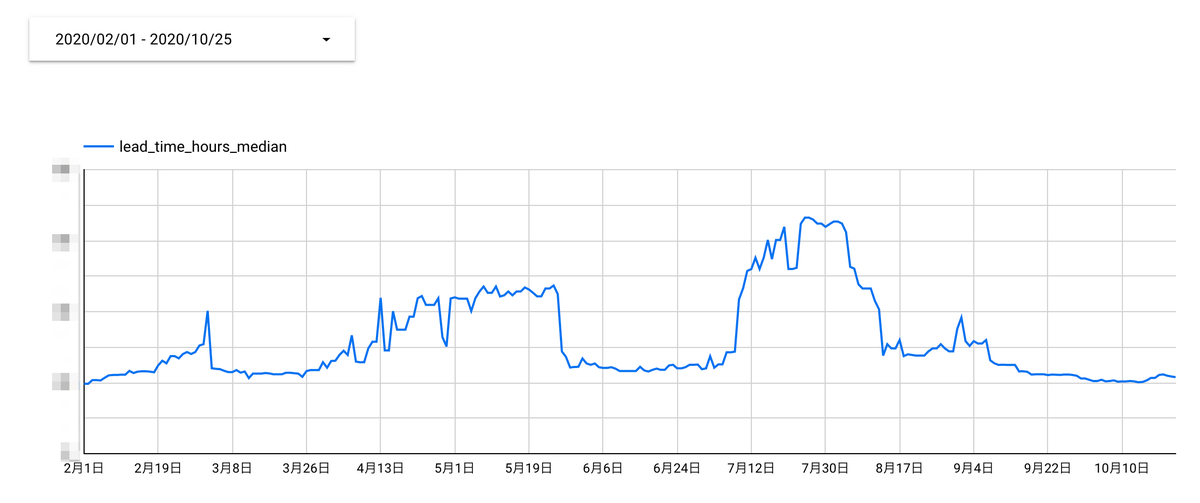
これのデータを使ってDataStudioで折れ線グラフを定義してあげると、こんな感じで変更のリードタイムが可視化される。左上の日付コントローラを触ることで範囲を変えることも出来る。
まとめ
以前PullRequestからチーム開発の生産性・健全性を測るCLIツールを書いてみた - $shibayu36->blog;で集計していた時は、データを入れる段階で統計情報に加工してしまっていたので、可視化する段階では柔軟な調整が出来なかった。今回PullRequestの生ログを入れるようにしたことで、可視化の段階でauthorのフィルタをしたり、移動平均の範囲を決めたり、レポジトリを絞り込んだり出来るようになった。結構便利に開発チームのデリバリのパフォーマンスの1指標を見れるようになったので満足。
*1:この記事の変更のリードタイムはLeanとDevOpsの科学の指標と厳密に一致してないことに注意。この記事では1commit〜mergeまでの時間を変更のリードタイムと置いている